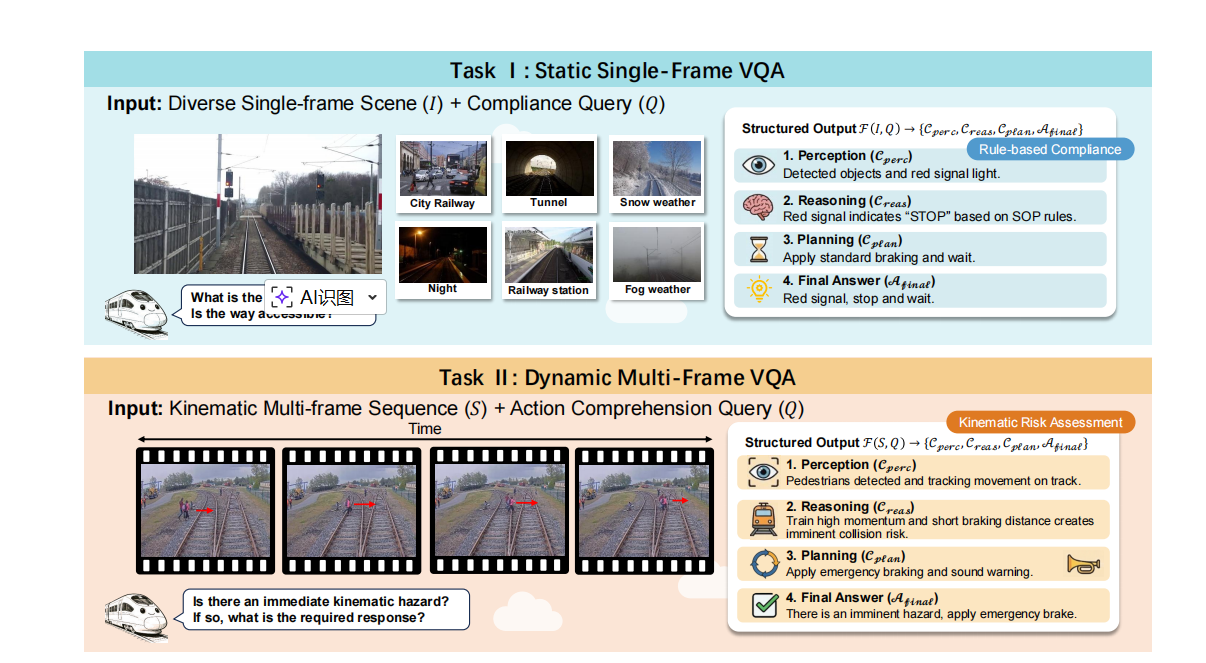
Method Overview
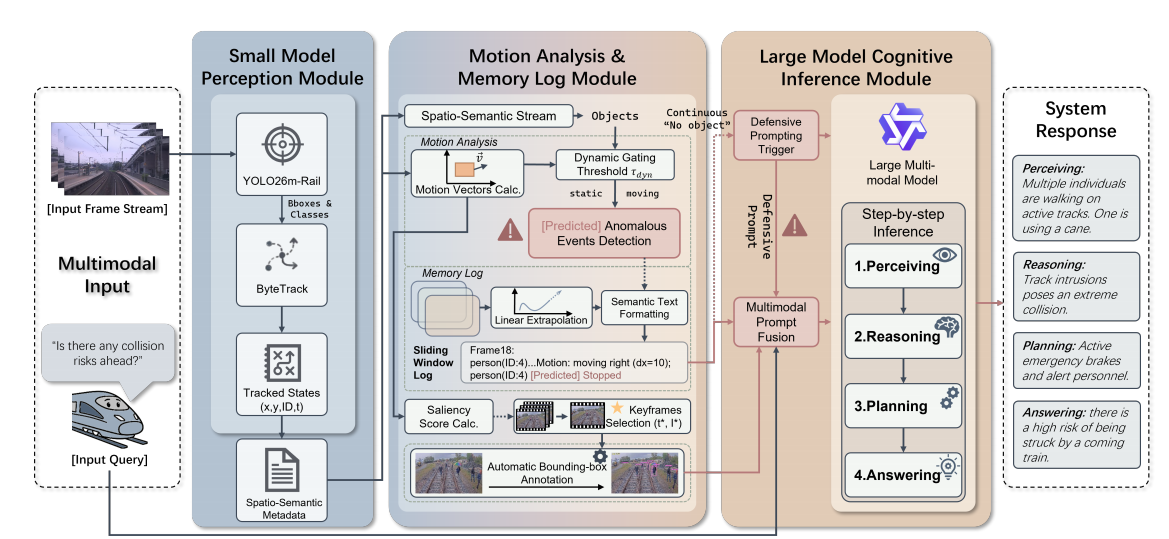
Fig. 1. Overview of the proposed RailVQA-CoM framework. This figure should serve as the central method illustration of the project page and visually summarize the full collaborative reasoning pipeline for automatic train operation scenarios. Compared with conventional end-to-end perception pipelines, RailVQA-CoM explicitly decomposes the decision-making process into lightweight front-end perception, temporal motion understanding, and high-level structured cognition.
More specifically, the figure is recommended to emphasize the interaction among three tightly coupled modules: (1) a small-model perception module responsible for efficient object detection, scene parsing, and target extraction in railway cab-view observations; (2) a motion analysis and memory log module that accumulates temporal evidence across frames, tracks dynamic entities, and organizes compact state descriptors for later reasoning; and (3) a large-model cognitive inference module that consumes structured visual evidence and produces interpretable outputs in the form of perception-level understanding, reasoning chains, planning suggestions, and final safety-aware answers.
This section should visually communicate the key design philosophy of RailVQA: using structured intermediate representations to reduce hallucination, improve explainability, and make multimodal reasoning more reliable for safety-critical train control tasks.